DataFrame 로딩 read_csv()
●read_csv()
csv 파일을 편리하게 DataFrame으로 로딩
read_csv()의 sep 인자를 콤마(,)가 아닌 다른 분리자로 변경하여 다른 유형의 파일(\t)도 로드 가능
예제는 https://github.com/chulminkw/PerfectGuide 권철민님 깃허브 소스파일을 사용했습니다.

파일명 : titanic_train.csv 이고 ,이 파일은 콤마(,)로 구분되어있다
type : DataFrame
데이터 추출 head() 및 DataFrame() 생성
●head(읽어올 데이터의 수) : 맨앞에서부터 데이터를 읽어올 데이터의 수 만큼 데이터를 읽어옴
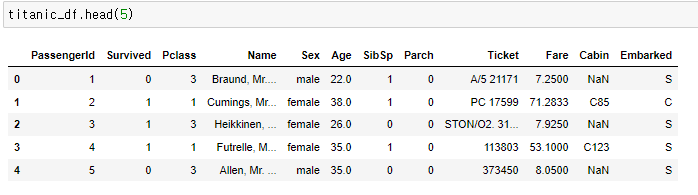
맨왼쪽에 0,1,2,3,4 의경우는 RDBMS에서의 KEY라고 이해하는게 좋을거 같다
실질적으로 출력하거나 배열로담을 수있는 값은 아니다.
(뒤에서 인덱스를 column 으로 만드는방식을 설명)
●DataFrame의 생성

딕셔너리 -> DataFrame을 만드는 방식
data_df = pd.DataFrame(dict1)
방식으로 "col1":{값}, "col2":{값} 식으로 사용,
값 : 배열이 들어갈 수 있음
index 값에 0,1,2,3 대신 값을 바꿔서 넣을 수 있음
●DataFrame의 컬럼명과 인덱스

titanic_df.columns : 해당 열의 값을 배열형태로
(dtype = object 는 string으로 이해)
titanic_df.index : 해당 인덱스의 범위를 보여준다
titanic_df.index.values =해당 인덱스값들을 배열로 보여준다
'# AI 이론 > Pandas' 카테고리의 다른 글
| 판다스(Pandas) DataFrame의 컬럼 데이터 셋 접근 (0) | 2022.01.07 |
|---|---|
| 판다스(Pandas) 정렬, 상호변환 (0) | 2022.01.07 |
| 판다스[Pandas] DataFrame Series,Filtering 추출 (0) | 2022.01.07 |
| 판다스(Pandas)란? (0) | 2022.01.07 |