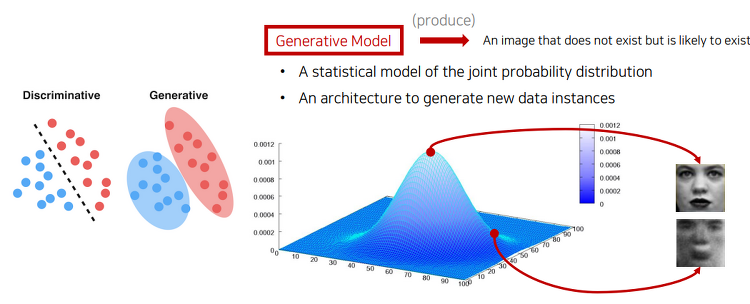
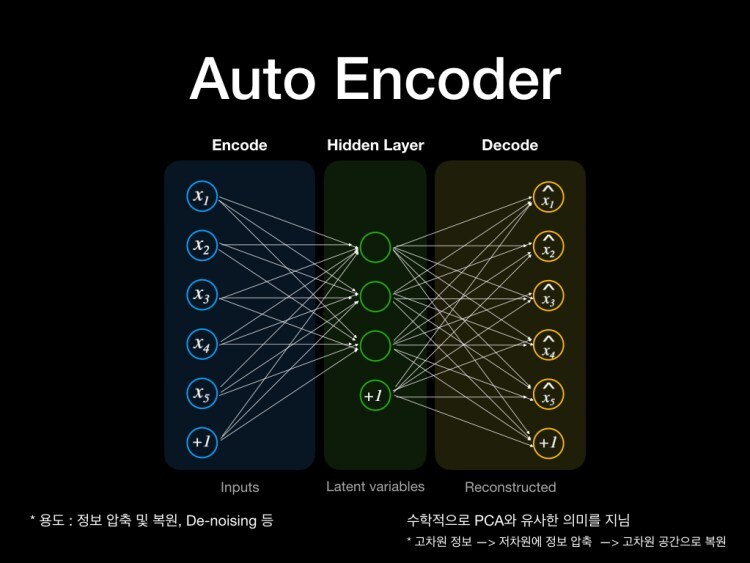
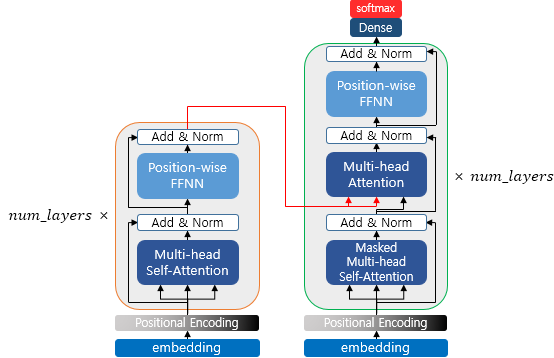
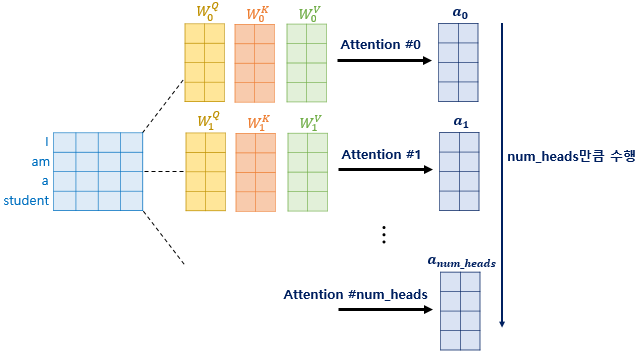
GAN 논문자료 GAN 딥러닝 논문 리뷰(Youtube - 동빈나) Youtube 동빈나 님의 자료와 GAN 논문 자료를 인용하여 작성하였습니다. GAN에 대해 설명하기 앞서, 필요한 내용인 Generative Models에 대해서 간략하게 설명하겠습니다. Generative Models Generative model이란 실존하지는 않지만 있을 법한 이미지를 생성할 수 있는 모델을 의미합니다. 사진의 왼쪽에서 보면 분류의 경우는 클래스간의 경계를 나눈 것이고, Generative 의 경우는 데이터간의 분포를 생성한 것입니다. 생성모델의 목표는다음과 같습니다. 입력 데이터의 분포에 근사하는 모델 G를 만드는 것 모델 G가 잘 작동한다는 것은 기존 이미지들의 분포를 잘 모델링 한다는 의미인데, 이때 2014..