트랜스포머 정리(2)
이전 글에 이어서 정리하는 글입니다. 앞의 글에서는 트랜스포머의 구조와 셀프 어텐션에 대해서 알아보았습니다. 멀티 헤드 어텐션(Multi-head Attention) 앞서 배운 어텐션에서는 $d_{model}$의 차원을
peaco.tistory.com
인코더에서 디코더로

지금까지 인코더에 대해서 정리를 했습니다. 인코더는 입력 데이터를 num_layers 수만큼의 연산을 순차적으로 수행 한 후,
마지막 층의 인코더의 출력을 디코더에 전달합니다.
그럼 이제 디코더도 num_layers 수만큼의 연산을 수행할텐데, 디코더의 역할은 무엇일까요?
디코더의 첫번째 서브층 : 셀프 어텐션과 룩-어헤드 마스크

위 그림을 살펴보면, 디코더도 인코더와 비슷한 점이 많습니다.
임베딩층과 포지셔널 인코딩을 거친 후, 문자행렬이 입력이 됩니다.
트랜스포머 또한 seq2seq와 마찬가지로 교사 강요(Teacher Forcing)을 통해 훈련되므로 학습 과정에서 디코더는 번역할 문장에 해당하는 <sos> je suis étudiant 문장 행렬을 한번에 입력 받습니다.
근데, 여기서 문제가 잠깐 발생합니다.우리가 이전에 배운 seq2seq의 디코더에 사용되는 RNN 계열의 신경망은 입력 단어를 매 시점마다 순차적으로 받고,다음 단어 예측을 현재 시점을 포함한 이전 시점에 입력된 단어들만 참고해서 예측했죠
반면, 트랜스포머는 문장 행렬로 한번에 받으니까 현재 시점의 단어를 예측할때 입력행렬문자를 통해 미래 시점의 단어까지 참고할 수 있게 됩니다.
예를 잠깐 들어보면, suis 를 예측할때 RNN의 seq2seq 이라면, <sos> je 만 참고할텐데,
트랜스포머의 경우 <sos> je suis étudiant 를 참고하게 됩니다.
이를 어떻게 해결할 수 있을까요?
1) 룩-어헤드 마스크(look-ahead mask)
말 그대로 "미리보는것에 대한 마스크"라는 의미 입니다. 역할은 이름에서부터 감이 올텐데, 현재시점에서 예측을 시행할때,
미래시점의 단어를 참고하지 못하게 해주는 방식입니다.

룩어헤드 마스크는 디코더의 첫번째 서브층에서 이루어집니다. 첫번째 서브층인 멀티-헤드 셀프 어텐션 층은 인코더의 첫번째 서브층인 멀티-헤드 셀프 어텐션과 동일안 연산을 수행하고, 어텐션 스코어 행렬에 마스킹을 적용합니다.

계산이 완료된 어텐션 스코어 행렬에 마스킹 처리를 하면 다음과 같습니다.

이제, 멀티-헤드 셀프 어텐션 함수 내부를 잠깐 살펴보겠습니다.
- 인코더의 셀프 어텐션 : 패딩 마스크를 전달
- 디코더의 첫번째 서브층(마스크드 셀프 어텐션) : 룩-어헤드 마스크 전달
- 디코더의 두번째 서브층(인코더 -디코더 어텐션) : 패딩 마스크를 전달
이와 같은데 다음은 룩-어헤드 마스크를 구현해보도록 하겠습니다.
# 디코더의 첫번째 서브층 : 룩 -어헤드 마스크
def create_look_ahead_mask(x):
seq_len = tf.shape(x)[1]
# band_part(-1,0) : 하 삼각행렬 생성,(0,-1) :상 삼각행렬, (0,0) : 대각행렬
look_ahead_mask = 1 - tf.linalg.band_part(tf.ones((seq_len,seq_len)),-1,0)
padding_mask = create_padding_mask(x)
return tf.maximum(look_ahead_mask,padding_mask)
"""
look_ahead_mask
[1,1,1] [1,0,0] [0,1,1]
[1,1,1] - [1,1,0] = [0,0,1]
[1,1,1] [1,1,1] [0,0,0]
"""print(create_look_ahead_mask(tf.constant([[1, 2, 0, 4, 5]])))
#outputs
tf.Tensor(
[[[[0. 1. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 1. 1. 1.]
[0. 0. 1. 0. 1.]
[0. 0. 1. 0. 0.]]]], shape=(1, 1, 5, 5), dtype=float32)
디코더의 두번째 서브층 : 인코더 디코더 어텐션
디코더의 두번째층은 멀티헤드 인텐션 층입니다. 이 멀티헤드 어텐션은 이전의 어텐션들과는 조금은 다른점 존재하는데,
셀프 어텐션이 아니다
라는 점에서 차이가 있습니다.
셀프 어텐션은 Query,Key,Value 가 모두 같은 경우를 말하지만 , 인코더-디코더 어텐션의 경우는 Query가 디코더인 행렬인 반면, Key,Value가 인코더 행렬이기 때문에 차이가 존재합니다.
| 인코더의 첫번째 서브층 | Query = Key =Value |
| 디코더의 첫번째 서브층 | Query = Key = Value |
| 디코더의 두번째 서브층 | Query : 디코더 행렬 / Key =Value : 인코더 행렬 |
디코더의 두번째 서브층을 잠깐 확인해보면, 화살표 2개가 있음을 알수 있습니다.

두개의 화살표는 각각 Key,Value를 의미하는데, 이는 인코더의 마지막 층에서 온 행렬로부터 얻습니다.
반면 검은색 하나의 선은 디코더의 Query임을 알 수 있습니다.
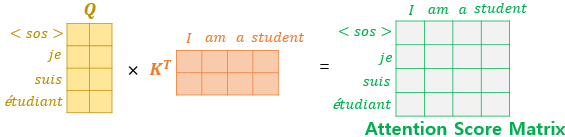
위의 그림은 인코더-디코더 어텐션층에서 어텐션 스코어 행렬을 구하는 과정입니다.
관련글
'# AI 이론 > DeepLearning' 카테고리의 다른 글
| [GAN] 생성적 적대 신경망 (0) | 2022.05.12 |
|---|---|
| Variational AutoEncoder(VAE) (0) | 2022.05.12 |
| 트랜스포머 정리(2) (0) | 2022.05.09 |
| 트랜스포머 정리(1) (0) | 2022.05.09 |
| 어텐션 메커니즘 (0) | 2022.05.09 |