RNN의 seq2seq 방식에는 두가지의 문제가 존재합니다.
- 하나의 고정된 크기에 모든 정보를 압축하려고 하기때문에, 정보 손실이 발생
- RNN의 고질적인 문제인 기울기 소실이 발생
이러한 문제로 기계 번역 분야에서 문장이 길수록 번역이 이상하게 되는 현상이 일어납니다.이를 해결 하기위해 고안된 기법이 바로 어텐션 메커니즘 입니다.
Attention Idea & Function
디코더에서 출력 단어를 예측하는 매 시점마다, "인코더에서의 전체 입력 문장을 다시 한 번 본다"
라는 점입니다. 전체입력을 동일한 비율로 보는것이 아니라, 연관이 있는 입력단어 부분을 조금더 집중적으로 보게됩니다.

어텐션 함수는 다음과 같이 표현합니다.
Attention(Q, K, V) = Attention Value
다음과 같은 방식으로 함수가 수행됩니다.
- 주어진 Query에 대해서 모든 Key와의 유사도를 구한다.
- 구해낸 유사도를 키와 맵핑되어있는 각각의 Value에 반영한다.
- 반영된 value를 모두 더해서 리턴한다. (이때 반환값을 Attention Value 라고합니다)
Dot-Product Attention
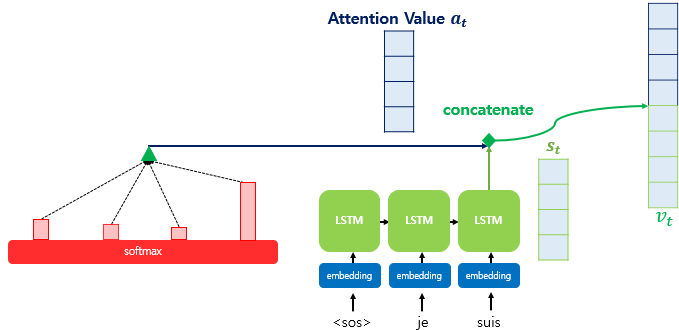
다음 그림은 Decoder에서 3번째 LSTM 셀에서 출력단어를 예측할 때의 모습을 보여줍니다.

여기서 주의깊게 봐야할 부분은 바로 인코더 부분의 Softmax 함수입니다.
Softmax results = I, am , a, student 단어 각각이 출력 단어를 예측할 때 얼마나 도움이 되는가? 에 대한 수치화 한값
직사각형의 크기가 클수록 도움이 되는 정도가 큰값
1) Attention Score

인코더의 시점을 각각 1,2, ...N 일때 인코더의 은닉상태는 $ h_1 , h_2 , ... ,h_n $
디코더의 현재시점 t에서의 디코더의 은닉상태를 $ s_t $
여기서 새로운 어텐션 스코어라는 값이 존재합니다. t시점에서의 어텐션값을 $ a_t $ 라고 하겠습니다.
어텐션 스코어란 현재 디코더의 시점 t에서 단어를 예측하기 위해, 인코더의 모든 은닉 상태 각각이 디코더의 현 시점의 은닉 상태와 얼마나 유사한지를 판단하는 스코어입니다.
어텐션 스코어 방식은 다음과 같습니다.
$$ score(s_{t},\ h_{i}) = s_{t}^Th_{i} $$

이와 같이 인코더의 모든 은닉 상태의 어텐션 스코어의 모음 값을 $ e^t $ 로 정의하고 수식은 다음과 같습니다.
$$ e^{t}=[s_{t}^Th_{1},...,s_{t}^Th_{N}] $$
2) 어텐션 분포 구하기

위에서 구한 어텐션 스코어 모음값 $ e^t $ 에 softmax 함수를 적용하여 모든 합이 1인 분포를 얻어냅니다.
소프트 맥스값을 적용한 어텐션 분포를 $ \alpha^t $ = softmax($ e^t $)로 정의 할수 있습니다.
3) 각 인코더의 어텐션 가중치와 은닉 상태를 가중합하여 어텐션 값 구하기

이때까지의 정보를 하나로 합치는 단계로, 어텐션의 최종 결과값을 얻기 위해 Encoder의 은닉상태와 어텐션 가중치를 곱하고, 최종적으로 모두 더합니다.
$$ a_{t}=\sum_{i=1}^{N} α_{i}^{t}h_{i} $$
이러한 어텐션 값 $ a^t $ 는 종종 인코더의 문맥을 포함한다하여, 컨텍스트 벡터 라고 불립니다.
4) 어텐션 값과 디코더 t 시점의 은닉상태 연결
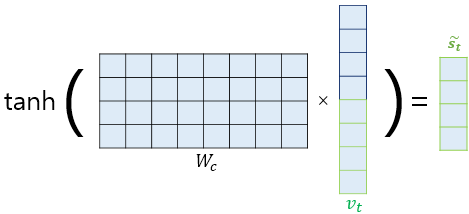
5) 출력층 연산의 입력이 되는 $ \tilde{{s}}_{t} $ 계산
관련글
'# AI 이론 > DeepLearning' 카테고리의 다른 글
| 트랜스포머 정리(2) (0) | 2022.05.09 |
|---|---|
| 트랜스포머 정리(1) (0) | 2022.05.09 |
| RNN,LSTM,GRU에 대해서 알아보자 (0) | 2022.05.03 |
| TensorFlow Protocol Buffer (0) | 2022.04.26 |
| 규제를 사용해 과대적합 피하기 (0) | 2022.04.20 |