2017년 구글이 발표한 논문인 "Attention is all you need"에서 나온 모델인 트랜스포머는 기존의 seq2seq의 구조인
인코더 디코더를 따르면서도, 어텐션만으로 구현이 가능한 모델입니다.
이 모델은 RNN을 사용하지 않고, 인코더-디코더 구조를 설계하였음에도 번역 성능에서도 RNN 보다 우수한 성능을 보여주었습니다.
트랜스포머 하이퍼 파라미터
아래에서 정의한 수치는 트랜스포머를 제안한 논문에서 사용한 수치로 하이퍼파라미터는 사용자가 모델 설계시 임의로 변경이 가능합니다.
$ d_{model} $ = 512
트랜스포머의 인코더와 디코더의 정해진 입력과 출력의 크기
임베딩 벡터의 차원 또한 $ d_model $ 이며, 인코더와 디코더가 다음 층의 인코더와 디코더로 보낼때도 차원 값 유지
num_layers = 6
트랜스포머에서 하나의 인코더와 디코더를 층으로 생각하였을때, 모델 내에 인코더와 디코더가 몇층으로 구성 되어있는지 의미
num_heads = 8
트랜스포머에서는 어텐션을 사용할 때, ,여러개로 분할해서 병렬로 어텐션을 수행하는데, 이때의 병렬 개수를 의미
$d_{ff} $ = 2048
트랜스포머 내부의 피드포워드 신경망이 존재하는데 해당 신경망의 은닉층의 크기를 의미
피드포워드 신경망의 입력층과 출력층의 크기는 $d_{model} $
트랜스포머(Transformer)
다음은 트랜스포머의 구조를 간단하게 나타낸 사진입니다.
"I am a student"를 임베딩 벡터를 통해서 입력을 보냅니다

이전 seq2seq 구조에서는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점을 가지는 구조였다면 이번에는 인코더와 디코더라는 단위가 N개로 구성되는 구조입니다.(n =6)
해당 논문에서는 num_layers = 6으로 6개의 인코더와 디코더가 사용 됩니다.


다음 그림을 살펴보면 인코더로 부터 정보를 받고, 디코더가 출력 결과를 만들어내는 트랜스포머 구조를 보여줍니다.
디코더는 seq2seq 구조와 비슷하게 <sos>를 입력으로 받고 <eos>가 나올때까지 연산을 진행합니다.
하지만 이 트랜스포머의 경우 인코더와 디코더는 단순히 각 단어의 임베딩 벡터들을 입력으로 받지않고, 임베딩 벡터에서 조정된 값을 받는데 이를 마저 살펴보겠습니다.
포지셔널 인코딩(Positional Encoding)
RNN이 자연어 처리에서 왜 유용했을까요?이유는 바로, 단어의 위치에 따라 단어를 순차적으로 입력받아서 처리하는 RNN의 특성으로 단어의 위치 정보를 가질수 있다는 점 입니다.
하지만 트렌스포머의 경우는 단어를 순차적으로 받지 않기 때문에, 다른 방식을 써야할 필요가 있습니다.
바로, 포지셔널 인코딩 입니다.
포지셔널 인코딩이란 각 단어의 임베딩 벡터에 위치 정보들을 더하여 모델의 입력으로 사용하는 방법을 말합니다.

위의 그림에서 입력으로 사용되는 임베딩 벡터들이 트랜스포머의 입력으로 사용되기 전 포지셔널 인코딩에 더해지는 것을 볼 수 있습니다. 이를 시각화 하면 다음과 같습니다.

근데, 포지셔널 인코딩이 어떤 값이길래 위치 정보를 반영시켜줄 수 있는걸까요?
트랜스포머는 위치 정보를 가진 값을 만들기 위해 다음과 같은 함수를 사용합니다.
$$ PE_{(pos,\ 2i)}=sin(pos/10000^{2i/d_{model}}) $$
$$ PE_{(pos,\ 2i+1)}=cos(pos/10000^{2i/d_{model}}) $$
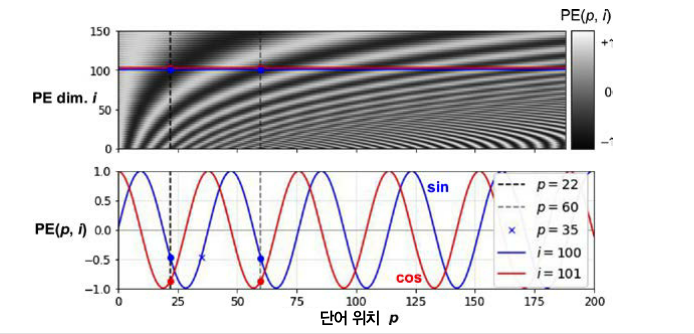
왜 이런 방식을 사용한걸까요?
첫번째로,
이 방법은 학습된 위치 임베딩과 동일한 선능을 내면서 임의의 긴 문장으로 확대할 수 있기 때문에 많이 사용됩니다.
위치마다 고유한 포지셔널 인코딩이 만들어지기 때문에 포지셔널 인코딩을 단어 임베딩에 더하면 모델이 문장에 있는 단어의 절대 위치를 알 수 있습니다.
(예를 들면, 22번째 위치에 있는 단어의 포지셔널 인코딩은 왼쪽 위 수직 점선으로 나타나 있고, 이 위치에 해당하는 인코딩은 고유합니다.)
두번째로,
진동 함수 선택에 따라 모델이 상대적인 위치도 학습 할 수 있습니다. (예를들어 p=22, p=60 인 38개 단어만큼 떨어져 있는 두 단어는 인코딩 차원 i=100, i=101 에서 항상 같은 값을 가집니다)사인 함수만 사용하게 되면, 모델이 p=22와 p=35 위치를 구별할 수 없습니다.
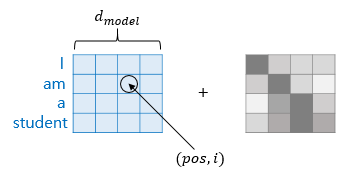
다음은 위에서 설명한 임베딩 벡터와 포지셔널 인코딩 행렬의 덧셈연산을 나타내는 그림입니다.
pos는 입력 문장에서의 임베딩 벡터의 위치를 나타내고, i는 임베딩 벡터 내의 차원의 인덱스를 의미합니다.(pos,i) = (1,2) 로 나타낼 수 있을 것 같습니다.
※ (pos,2i)일때는 sin 함수, (pos,2i + 1)일때는 코사인 함수를 사용합니다.
어텐션(Attention)
트랜스포머에서 사용되는 세가지 어텐션을 간단하게 살펴보겠습니다.
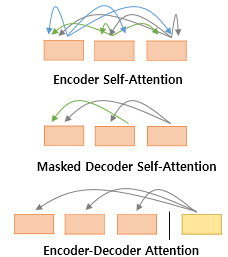
첫번째 셀프 어텐션은 인코더에서 이루어지고, 두번째,세번째 그림은 디코더에서 이루어 집니다.
self attention은 본질적으로 Query,Key,Value 값이 모두 동일한 경우를 말합니다.
반면에 세번째 그림 Encoder-Decoder Attention에서는 Query가 디코더의 벡터인 반면, Key,Value가 인코더 벡터이므로 self attention 이라고 하지 않습니다.
※ 주의할점 : 여기서 Query,Key가 같다는것은 벡터의 값이 같은것이 아닌 출처가 같다는것입니다.
정리하면 다음과 같습니다.
Encoder Self-Attention : Query = Key = Value
Masked Decoder Self-Attention : Query = Key = Value
Encoder-Decoder Attention : Query : 디코더 벡터 / Key = Value : 인코더 벡터
다음 그림은 트랜스포머의 구조에서 세가지 어텐션이 어디에서 이루어지는지를 나타내는 그림입니다.

인코더(Encoder)
다음은 인코더의 구조입니다.
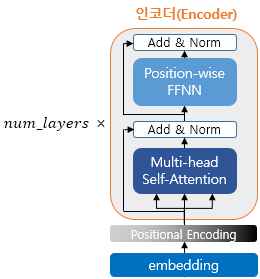
트랜스포머의 구조를 살펴보면, 하이퍼파라미터인 num_layers 개수 만큼 인코더 층을 쌓습니다.
인코더를 하나의 층이라고 생각하면, 인코더에는 2개의 서브층(sub-layer)가 존재합니다.
피드 포워드 신경망(FeedForward Neural Network)
피드포원드 신경망은 순방향 신경망 이라고 생각하면 됩니다.
멀티헤드 셀프 어텐션(Multi-head Self-Attention)
셀프 어텐션에서 멀티헤드가 붙었는데, 이는 셀프 어텐션을 병렬적으로 사용했다라는 의미입니다.
1.셀프 어텐션 이란?
앞에서 저희는 어텐션이란 것에 대해서 배웠습니다. 어텐션에 대해서 다시한번 복습할겸 간단하게 설명하면,
주어진 Query에 대해서 모든 Key와의 유사도를 구한후, 유사도를 가중치로하여, Key에 매핑되는 값을 반영합니다.
그 후, 유사도가 반영된 값을 모두 가중합으로 리턴하는 방식
셀프 어텐션이라는 것은 어텐션을 자기 자신에게 수행한다는 의미를 가진것입니다.
앞서 seq2seq에서 어텐션을 사용할 경우 Q,K,V의 정의를 다시 생각해보면,
Q,K,V = t 시점의 디코더셀에서의 은닉상태 / 모든 시점의 인코더 셀의 은닉 상태 / 모든 시점의 인코더 셀의 은닉 상태
로 표현 할 수 있습니다.
이때 타임스텝 t 라는 것은 계속 변화하면서 반복적으로 쿼리를 수행하므로 결국 전체시점에 대해 일반화가 가능합니다.
Q,K,V = 모든 시점의 디코더셀에서의 은닉상태 / 모든 시점의 인코더 셀의 은닉 상태 / 모든 시점의 인코더 셀의 은닉 상태
로 표현 할 수 있습니다.
이때, Q는 디코더 셀 , K는 인코더 셀이라는 다른 값을 가지고 있었지만 ,셀프 어텐션의 경우 Q,K,V가 모두 동일 하므로 다음과 같이 나타낼 수 있습니다.
Q : 입력 문장의 모든 단어 벡터들
K : 입력 문장의 모든 단어 벡터들
V : 입력 문장의 모든 단어 벡터들
그렇다면 셀프 어텐션으로는 도대체 어떤 효과를 얻을 수 있는건가요?

다음 문장을 해석해보면, "그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤했기 때문이다" 라는 문장이있습니다. 그런데 여기서 그것(It)이 나타내는 의미가 뭘까요? 영어를 배운 저희는 동물이라는것을 당연히 알 수 있습니다.
하지만 기계도 저희처럼 생각 할 수 있을까요?
그렇지 않습니다. 하지만 셀프 어텐션을 통해 입력 문장 내의 단어들끼리 유사도를 구하면서 it 이 animal과 높은 연관성이 있다는 것을 찾아 낼 수 있습니다.
다음으로는 셀프 어텐션이 어떻게 작동하는지에 대해서 알아보겠습니다.
2. 셀프 어텐션 작동방식
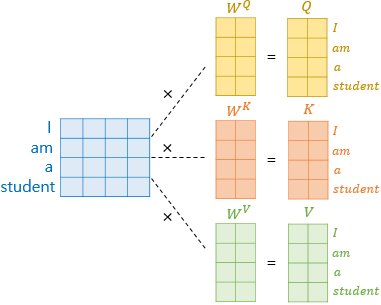
기존의 셀프 어텐션은 입력 문장의 모든 단어 벡터들을 가지고 수행한다고 했습니다.
사실, 셀프 어텐션은 인코더의 초기 입력인 $ d_model $의 차원을 가지는 단어 벡터들을 사용하여 셀프 어텐션을 수행하는것 아닙니다.
우선 각 단어 벡터들로 부터 $ Vector_Q , Vector_K , Vector_V $를 얻는 작업을 거칩니다.
논문에서는 $ d_model $=512, num_heads = 8을 나눈 값인 64차원 값을 갖는 Q,K,V벡터로 변환 했습니다.
다음은 예문에서 student 라는 단어 벡터를 Q,K,V 벡터로 변환하는 과정입니다.
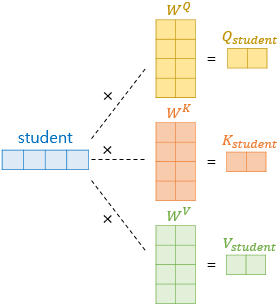
student의 차원은 512로, 더 작은 벡터 Q,K,V벡터는 가중치 행렬을 곱하면서 생성됩니다.
각 가중치 행렬 W는 $ d_{model} × (d_{model}\text{/num_heads}) $의 크기를 가지는데,
student = $ (1,512) $, W= $ (512,(64)) $를 통해 Q,K,V는 (1,64)의 크기를 갖는 행렬이 만들어집니다.
3. 스케일드 닷-프로덕트 어텐션(Scaled dot-product Attention)
$ Vector_(Q,K,V) $를 얻었다면
1. 각 $ Vector_Q $ 는 모든 $ Vector_K $에 대해서 어텐션스코어를 구한후,
2. 어텐션 분포를 구한 뒤 ,
3. 모든 $ Vector_V $를 가중합하여 어텐션 값 or 컨텍스트 벡터를 구하게 됩니다.
4. 이를 모든 $ Vector_Q $에 대해서 반복합니다.
여기서 $ score(q, k)=q⋅k $가 아닌 특정값으로 나눈(스케일링하는) $ score(q, k)=q⋅k/\sqrt{n} $로 계산을 진행합니다.
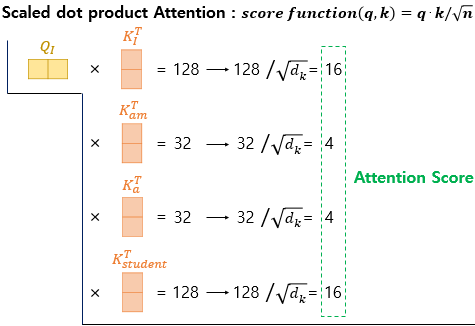
단어 "I" 에 대한 Q벡터를 기준으로, "I" ,"am", "a", "student"에 대해 모두 어텐션 스코어를 각각 구합니다.
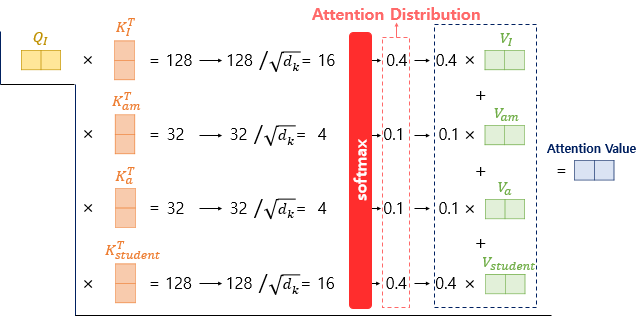
이를 이제, 어텐션 분포(소프트맥스 함수)를 구한뒤, 각 $ Vector_V $ 와 가중합을 하여 어텐션 값을 구합니다.
※이때 "I"에 대한 어텐션 값, 컨텍스트 벡터라고 합니다.
이와 같은 과정을 "am", "a","student" 과정에 모두 반복합니다.
스케일링 닷 프로덕트 어텐션 구현
def scaled_dot_product_attention(query, key, value, mask) :
# query : (batch_size, num_heads, query_length, d_model/num_heads)
# key : (batch_size, num_heads, key_length, d_model/num_heads)
# value : (batch_size, num_heads, value_length, d_model/num_heads)
# padding_mask : (batch_size, 1, 1, key_length)
matmul_qk = tf.matmul(query,key, transpose_b=True)
#Scaling
# dk의 루트값으로 나눈다
depth = tf.cast(tf.shape(key)[-1], tf.float32)
logits = matmul_qk / tf.math.sqrt(depth)
# 마스킹, 어텐션 스코어 행렬의 마스킹 할 위치에 매우 작은 음수값을 넣는다.
# 매우 작은값이므로 소프트맥스 함수를 지나면 행렬의 해당 위치는 0이 된다.
if mask is not None :
logits += (mask * -1e9)
# 소프트맥스 함수는 마지막 차원인 key의 문장 길이 방향으로 수행
# attention_weight = (batch_size, num_heads,d query_length, key_length)
attention_weights = tf.nn.softmax(logits,axis=-1)
# output : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
output = tf.matmul(attention_weights, value)
return output, attention_weights
근데 이렇게 하면 너무 오래걸리고 일일히 따로 연산해야 하는건가요?
그럴 필요 없습니다.
4. 행렬 연산으로 일괄 처리
위의 스케일드 닷-프로덕트 어텐션은 벡터연산이 아닌 행렬 연산을 통해 일괄 연산이 가능합니다.
다음 그림을 살펴 보겠습니다.
1.Q와 $ K^T $ 를 내적 하여, 64 x64 크기의 행렬을 만들고(그림에서는 4x4행렬이 만들어지겠네요)
2.나온 행렬을 차원의 루트값으로 나눈후 소프트맥스를 취한후,
3. V와 내적을 수행 합니다.
$$ Attention(Q, K, V) = softmax({QK^T\over{\sqrt{d_k}}})V $$
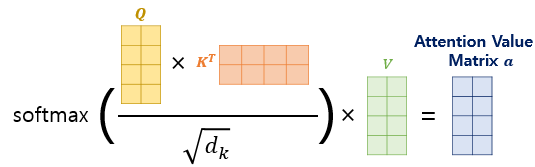
마지막으로 위의 행렬 연산에 사용된 행렬의 크기를 정리 해보겠습니다.
| 입력 문장의 길이 | seq_len |
| 문장 행렬의 크기 | (seq_len, $ d_model $) |
1. 이 문장 행렬에 3개의 가중치를 곱하여 K,Q,V 행렬 생성 (seq_len, $ d_{model}/num_heads $)
Q,K 벡터의 차원을 $ d_k $라고 하고, V벡터의 차원을 $ d_v $라고 해보면,
Q,K 행렬 : (seq_len, $ d_k $), V 행렬 : (seq_len, $ d_v $)
2.가중치 행렬
$W^{Q}$와 $W^{K}$는 ( $ d_{model}, d_k $ ) 크기, $W^V$ 는 {$ d_{model}, d_v$}의 크기를 가진다.
관련글
핸즈온 머신러닝 사이킷런, 케라스, 텐서플로 2를 활용한 머신러닝, 딥러닝 완벽 실무 | 텐서플로 2
1) 트랜스포머(Transformer)
* 이번 챕터는 앞서 설명한 어텐션 메커니즘 챕터에 대한 사전 이해가 필요합니다. 트랜스포머(Transformer)는 2017년 구글이 발표한 논문인 Attentio ...
wikidocs.net
'# AI 이론 > DeepLearning' 카테고리의 다른 글
| 트랜스포머 정리(3) (0) | 2022.05.10 |
|---|---|
| 트랜스포머 정리(2) (0) | 2022.05.09 |
| 어텐션 메커니즘 (0) | 2022.05.09 |
| RNN,LSTM,GRU에 대해서 알아보자 (0) | 2022.05.03 |
| TensorFlow Protocol Buffer (0) | 2022.04.26 |