Protocol Buffer
CSV,XML,JSON등 여러 직렬화 방식 중 하나로 구글에서 개발한 이진 직렬화 방식
직렬화(Serialization)란
직렬화란 시스템 내부에서 사용하는 개체를 다른 시스템에서도 사용할 수 있도록 바이트 형태로 데이터를 변환하는 기술을 뜻한다. 예를들면 Java,Python에서 사용하던 객체 방식과 Node.js에서는 형식이 다르기 때문에 모두가 같은 데이터를 사용하도록 공통화 작업을 한다고 생각하면 된다
ProtoBuf 사용순서
- protoBuf 포맷으로 데이터 구조를 정의
- 컴파일하기(각 타겟 언어별 protoc 컴파일러 사용)
- 컴파일된 모듈 각 언어에서 코드레벨로 로드하기
ProtoBuf 파일 생성
%%writefile person.proto
syntax = "proto3";
message Person {
string name = 1;
int32 id = 2;
repeated string email = 3;
}ProtoBuf Compile
!protoc person.proto --python_out=. --descriptor_set_out=person.desc --include_imports컴파일의 결과로 person_by2.py가 생성됩니다.
!ls person* # person.desc person_pb2.py person.proto
from person_pb2 import Person
person = Person(name="Al", id=123, email=["a@b.com"]) # Person 생성
print(person) # Person 출력TensorFlow Protocol Buffer
```proto
syntax = "proto3";
message BytesList { repeated bytes value = 1; }
message FloatList { repeated float value = 1 [packed = true]; }
message Int64List { repeated int64 value = 1 [packed = true]; }
message Feature {
oneof kind {
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
message Features { map<string, Feature> feature = 1; };
message Example { Features features = 1; };
```- [packed = true]는 효율적인 인코딩을 위해 반복적인 수치 필드에 사용됩니다.
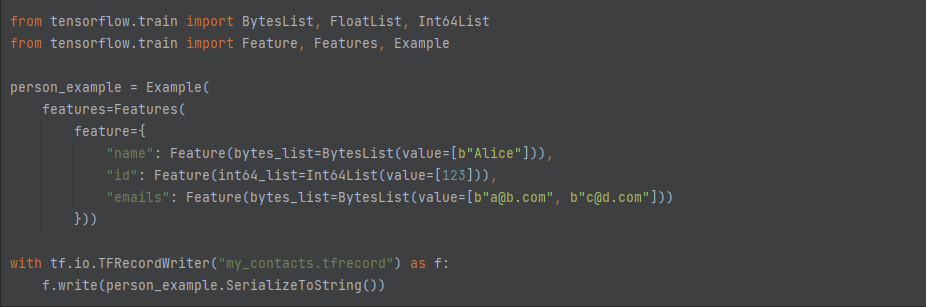
- Feature는 BytesList, FloatList,Int64List중 하나를 담고있습니다.
- Features는 특성이름과 특성값을 매핑한 딕셔너리를 가집니다.
- Example은 하나의 Feature 객체를 가지게 되는데, 위의 코드는 Person과 동일한 tf.train.Example객체를만들고 TFRecord 파일에 저장하는 방법을 나타냅니다
Reading and Parsing Example Protocol Buffer
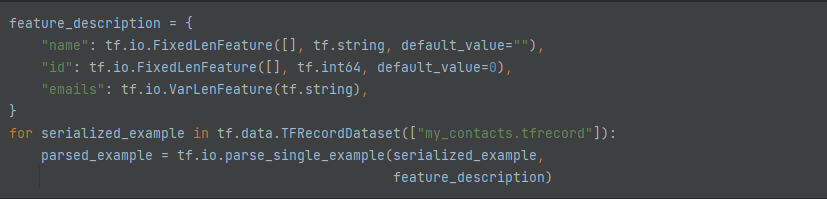
직렬화된 Example 프로토콜 버퍼를 읽기 위해서 tf.data.TFRecordDataset를 다시한번더 사용하고 ,tf.io.parse_single_example을 사용하여 각 Example을 파싱합니다
- 고정 길이 특성은 보통의 텐서로 파싱되지만 가변 길이 특성은 희소 텐서로 파싱됩니다.
tf.sparse.to_dense()로 희소 텐서를 밀집 텐서로 변환할 수 있지만 여기에서는 희소 텐서의 값을 바로 참조하는것이 간단합니다.

'# AI 이론 > DeepLearning' 카테고리의 다른 글
| 어텐션 메커니즘 (0) | 2022.05.09 |
|---|---|
| RNN,LSTM,GRU에 대해서 알아보자 (0) | 2022.05.03 |
| 규제를 사용해 과대적합 피하기 (0) | 2022.04.20 |
| 배치 정규화 (0) | 2022.04.20 |
| 케라스를 이용한 인공 신경망 만들기(하이퍼파라미터 튜닝) (0) | 2022.04.19 |