https://www.kaggle.com/competitions/dogs-vs-cats/data
Dogs vs. Cats | Kaggle
www.kaggle.com
핸즈 온 머신러닝2에서 14강인 CNN(Convoltuional Neural Network)를 공부하고 나서 배웠던 것을 써먹을 만한것이 없을까 하다가 캐글의 개와 고양이 사진을 분류하는 모델을 만들어보면서 부족한 부분을 다시 정리하고자 합니다.
인간은 고양이와 개를 분류하기 정말 쉽습니다. 그냥 바로 마주치면 아니까...
하지만 컴퓨터는 그렇지 않습니다. 컴퓨터는 인간과 같이 데이터를 파악하는것이 아니라 자신만의 룰을 만들어가면서 분류하기 때문입니다.
DataSet은 위의 Kaggle 사이트에 들어가서 다운받을 수 있습니다.
IMPORT MODULES
# For Preparing Data
import os
from zipfile import ZipFile
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import random
# For Building Model
import keras.backend as K
import tensorflow as tf
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Conv2D,BatchNormalization,MaxPooling2D,Dropout, Flatten, Dense
from functools import partial
# Callbacks
from keras.callbacks import Callback
from keras.callbacks import EarlyStopping,ReduceLROnPlateau
# Split Datasets
from sklearn.model_selection import train_test_split
# Data Augmentation
from keras.preprocessing.image import ImageDataGenerator,load_img
# Transfer learning
from keras import applications
from keras import Model
from keras.layers import Input, GlobalAveragePooling2D
Define Constants
데이터의 경로와 해당 이미지의 입력데이터 크기를 정해줍니다.
FAST_RUN =True 일경우에는 epoch를 15로 설정합니다. False 일경우 50으로 설정합니다.
DATA_DIR = "../data"
TRAIN_DIR ="../data/train/"
TEST_DIR = "../data/test1/"
ZIP_TRAIN_DIR = "../data/train.zip"
ZIP_TEST_DIR = "../data/test1.zip"
IMAGE_WIDTH = 128
IMAGE_HEIGHT = 128
IMAGE_CHANNELS = 3
input_shape = (IMAGE_HEIGHT, IMAGE_WIDTH, IMAGE_CHANNELS)
FAST_RUN = True
if not os.path.exists(DATA_DIR):
os.mkdir(DATA_DIR)
with ZipFile(ZIP_TRAIN_DIR) as zf:
zf.extractall(DATA_DIR)
with ZipFile(ZIP_TEST_DIR) as zf:
zf.extractall(DATA_DIR)
Prepare out training data into data frame
훈련데이터셋을 데이터프레임의 형태로 변환합니다.
강아지 일경우 1, 고양이 일경우 0으로 변환
train_files = os.listdir(TRAIN_DIR)
categories = []
for file in train_files:
category = file.split('.')[0]
# if dog, 1
if category == "dog":
categories.append(1)
else:
categories.append(0)
df = pd.DataFrame({
'filename': train_files, #2 cols (filename, category)
'category': categories,
})
Build Model
해당 모델에서는 CNN을 기반한 모델을 생성합니다.
CNN의 각층 구조는 Conv2D, BN, Pooling, Dropout 으로 구성되어있습니다.
def add_FE_layer(model, num_filters, kernel_size, activation, input_shape, pool_size, drop_rate):
if input_shape is None :
model.add(Conv2D(num_filters,kernel_size,activation=activation))
else :
model.add(Conv2D(num_filters,kernel_size, activation = activation, input_shape= input_shape))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size = pool_size))
model.add(Dropout(drop_rate))
return model
filters = [64,128]
model = Sequential()
model = add_FE_layer(model,32,(3,3),"relu",input_shape,(2,2) ,0.25)
for filter in filters :
model = add_FE_layer(model,filter,(3,3),"relu",None,(2,2),0.25)
# FC Layers
model.add(Flatten())
model.add(Dense(units=512,activation="relu"))
model.add(Dropout(0.5))
model.add(Dense(units=2,activation="softmax"))
model.compile(loss="categorical_crossentropy",optimizer="rmsprop",metrics=["accuracy"])
model.summary()
CallBacks
콜백함수는 EarlyStopping, ReduceLROnPlateau 를 사용합니다.
EarlyStopping : 모델이 더 이상 학습을 못할 경우, 학습 도중 미리 학습을 종료시키는 콜백함수
ReduceLROnPlateau : 모델의 개선이 없을 경우 ,Learning Rate를 조절해 모델의 개선을 유도하는 콜백함수
early_stop = EarlyStopping(patience=10)
learning_rate_reduction = ReduceLROnPlateau(monitor="val_acc",
factor=0.5,
patience=2,
verbose=1,min_lr=0.00001)
"""
factor = Learning Rate를 얼마나 감소시킬것인가? (learning_rate * factor)로 갱신
monitor = ReduceLROnPlateau의 기준디 되는값
"""
callbacks = [early_stop,learning_rate_reduction]
Prepare Traning & Validating data
훈련세트와 검증세트를 분리합니다.
밑의 category의 그래프를보면 반반씩 레이블이 고르게 나누어진것을 알수 있습니다.
train_df, valid_df = train_test_split(df,test_size=0.2, random_state=42)
train_df.reset_index(drop=True)
valid_df.reset_index(drop=True)
total_train = train_df.shape[0]
total_valid = valid_df.shape[1]
batch_size= 15
train_df["category"].value_counts().plot.bar()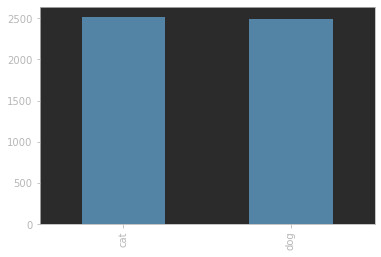
Data Augmentation
데이터 증식을 위해서 케라스에서 제공하는 ImageGenerator를 사용합니다.
이미지의 위치변경, 회전, 좌우반전을 했을때의 데이터를 증식시켜 학습 데이터를 늘려서 이러한 변조에 강하게 모델을 학습시킬 수 있습니다.
# Training Set Augmentation
train_datagen = ImageDataGenerator(
rotation_range=15,
rescale=1./255.,
shear_range=0.1,
zoom_range=0.2,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
)
train_generator = train_datagen.flow_from_dataframe(
train_df,
TRAIN_DIR,
x_col = "filename",
y_col = "category",
target_size = (IMAGE_HEIGHT,IMAGE_WIDTH),
class_mode = "categorical",
batch_size =batch_size
)
# Validation Set Augmentation
valid_datagen = ImageDataGenerator( rescale=1./255)
valid_generator = valid_datagen.flow_from_dataframe(
valid_df,
TRAIN_DIR,
x_col="filename",
y_col="category",
target_size = (IMAGE_HEIGHT,IMAGE_WIDTH),
class_mode="categorical",
batch_size=batch_size
)ImageGenerator의 파라미터를 잠깐 살펴보면 다음과 같습니다.
rotation_range : 이미지의 최대 회전각도를 지정합니다. 최대 20도까지 회전
rescale : 이미지의 정규화를 위해 사용합니다. 각 이미지 별로 255로 나눈값으로 데이터가 변형
width,height_shift_range : 상하좌우 이미지의 이동하는 백분율을 설정
horizonal_flip: True시 이미지의 수평 반전을 시켜줍니다. 이 옵션의 경우는 데이터셋의 이해가 필요합니다.
동물의 경우 좌우가 반전되어도 알아 볼 수 있지만, 손글씨의 경우는 알아볼 수 없습니다.
Training Results
_epochs = 15 if FAST_RUN else 50
history = model.fit(
train_generator,
epochs= _epochs,
validation_data= valid_generator,
validation_steps= valid_df.shape[0] // batch_size,
steps_per_epoch =total_train // batch_size,
callbacks =callbacks
)Epoch 1/15
1333/1333 [==============================] - ETA: 0s - loss: 1.4412 - accuracy: 0.6055WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 379s 281ms/step - loss: 1.4412 - accuracy: 0.6055 - val_loss: 0.8531 - val_accuracy: 0.5612 - lr: 0.0010
Epoch 2/15
1333/1333 [==============================] - ETA: 0s - loss: 0.6514 - accuracy: 0.6724WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 370s 278ms/step - loss: 0.6514 - accuracy: 0.6724 - val_loss: 1.1472 - val_accuracy: 0.6923 - lr: 0.0010
Epoch 3/15
1333/1333 [==============================] - ETA: 0s - loss: 0.6023 - accuracy: 0.7179WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 376s 282ms/step - loss: 0.6023 - accuracy: 0.7179 - val_loss: 0.5162 - val_accuracy: 0.7680 - lr: 0.0010
Epoch 4/15
1333/1333 [==============================] - ETA: 0s - loss: 0.6113 - accuracy: 0.7204WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 365s 274ms/step - loss: 0.6113 - accuracy: 0.7204 - val_loss: 1.0723 - val_accuracy: 0.6120 - lr: 0.0010
Epoch 5/15
1333/1333 [==============================] - ETA: 0s - loss: 0.5784 - accuracy: 0.7403WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 364s 273ms/step - loss: 0.5784 - accuracy: 0.7403 - val_loss: 2.5350 - val_accuracy: 0.6743 - lr: 0.0010
Epoch 6/15
1333/1333 [==============================] - ETA: 0s - loss: 0.5647 - accuracy: 0.7519WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 372s 279ms/step - loss: 0.5647 - accuracy: 0.7519 - val_loss: 3.2756 - val_accuracy: 0.5954 - lr: 0.0010
Epoch 7/15
1333/1333 [==============================] - ETA: 0s - loss: 0.5419 - accuracy: 0.7620WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 368s 276ms/step - loss: 0.5419 - accuracy: 0.7620 - val_loss: 1.6826 - val_accuracy: 0.6414 - lr: 0.0010
Epoch 8/15
1333/1333 [==============================] - ETA: 0s - loss: 0.5189 - accuracy: 0.7711WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 367s 275ms/step - loss: 0.5189 - accuracy: 0.7711 - val_loss: 0.4272 - val_accuracy: 0.8348 - lr: 0.0010
Epoch 9/15
1333/1333 [==============================] - ETA: 0s - loss: 0.5024 - accuracy: 0.7811WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 368s 276ms/step - loss: 0.5024 - accuracy: 0.7811 - val_loss: 0.4786 - val_accuracy: 0.8218 - lr: 0.0010
Epoch 10/15
1333/1333 [==============================] - ETA: 0s - loss: 0.4931 - accuracy: 0.7835WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 367s 275ms/step - loss: 0.4931 - accuracy: 0.7835 - val_loss: 0.7910 - val_accuracy: 0.8094 - lr: 0.0010
Epoch 11/15
1333/1333 [==============================] - ETA: 0s - loss: 0.4826 - accuracy: 0.7942WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 598s 449ms/step - loss: 0.4826 - accuracy: 0.7942 - val_loss: 0.3789 - val_accuracy: 0.8212 - lr: 0.0010
Epoch 12/15
1333/1333 [==============================] - ETA: 0s - loss: 0.4586 - accuracy: 0.8035WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 622s 467ms/step - loss: 0.4586 - accuracy: 0.8035 - val_loss: 0.3645 - val_accuracy: 0.8571 - lr: 0.0010
Epoch 13/15
1333/1333 [==============================] - ETA: 0s - loss: 0.4582 - accuracy: 0.8038WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 567s 425ms/step - loss: 0.4582 - accuracy: 0.8038 - val_loss: 0.5780 - val_accuracy: 0.7826 - lr: 0.0010
Epoch 14/15
1333/1333 [==============================] - ETA: 0s - loss: 0.4417 - accuracy: 0.8112WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
1333/1333 [==============================] - 393s 294ms/step - loss: 0.4417 - accuracy: 0.8112 - val_loss: 0.3979 - val_accuracy: 0.8338 - lr: 0.0010
Epoch 15/15
1333/1333 [==============================] - ETA: 0s - loss: 0.4336 - accuracy: 0.8143WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,val_loss,val_accuracy,lr
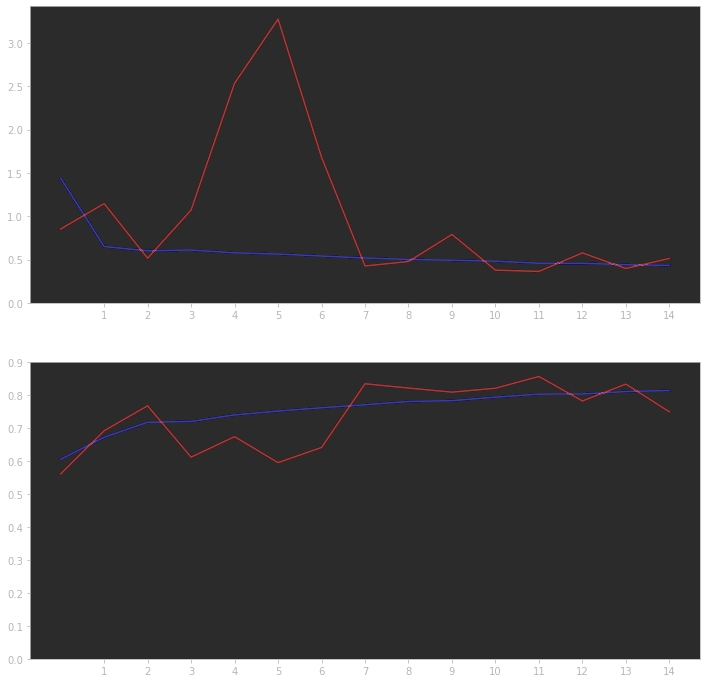
1333/1333 [==============================] - 398s 299ms/step - loss: 0.4336 - accuracy: 0.8143 - val_loss: 0.5140 - val_accuracy: 0.7497 - lr: 0.0010정확도는 81.43%, 검증데이터에 대한 정확도는 75%정도가 나왔습니다.
생각보다 높게 나오지는 않았는데 모델이 깊지않고, 에포크 수도 적어서 그런 거 같습니다.
다음은 훈련시 정확도와 손실에 대한 그래프입니다.
Transfer Learning(VGG16 Model)
keras.applications의 base_model을 사용해보겠습니다.
다음과같이 VGG16 Model의 기본 모델을 제공합니다.
base_model = applications.vgg16.VGG16(weights="imagenet",include_top = False, input_shape=input_shape)
base_model.summary()Model: "vgg16"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 128, 128, 3)] 0
block1_conv1 (Conv2D) (None, 128, 128, 64) 1792
block1_conv2 (Conv2D) (None, 128, 128, 64) 36928
block1_pool (MaxPooling2D) (None, 64, 64, 64) 0
block2_conv1 (Conv2D) (None, 64, 64, 128) 73856
block2_conv2 (Conv2D) (None, 64, 64, 128) 147584
block2_pool (MaxPooling2D) (None, 32, 32, 128) 0
block3_conv1 (Conv2D) (None, 32, 32, 256) 295168
block3_conv2 (Conv2D) (None, 32, 32, 256) 590080
block3_conv3 (Conv2D) (None, 32, 32, 256) 590080
block3_pool (MaxPooling2D) (None, 16, 16, 256) 0
block4_conv1 (Conv2D) (None, 16, 16, 512) 1180160
block4_conv2 (Conv2D) (None, 16, 16, 512) 2359808
block4_conv3 (Conv2D) (None, 16, 16, 512) 2359808
block4_pool (MaxPooling2D) (None, 8, 8, 512) 0
block5_conv1 (Conv2D) (None, 8, 8, 512) 2359808
block5_conv2 (Conv2D) (None, 8, 8, 512) 2359808
block5_conv3 (Conv2D) (None, 8, 8, 512) 2359808
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
=================================================================
Total params: 14,714,688
Trainable params: 14,714,688
Non-trainable params: 0
_________________________________________________________________
VGG16 model의 FC층을 만들어보겠습니다.
다음과 같은 계층이 생성됩니다.
# base_model의 층들의 파라미터들이 훈련동안 변하면 안되기 때문에, trainable = False로 설정합니다.
for layer in base_model.layers:
layer.trainable=False
m = base_model.layers[-1].output
m = GlobalAveragePooling2D()(m)
m = Dense(100,activation="relu")(m)
m = Dropout(0.4)(m)
m = Dense(64,activation="relu")(m)
m = Dense(2, activation="softmax")(m)
transfer_model = Model(base_model.input, m)
transfer_model.compile(loss="categorical_crossentropy",optimizer="rmsprop", metrics=["accuracy"])
transfer_model.summary()Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 128, 128, 3)] 0
block1_conv1 (Conv2D) (None, 128, 128, 64) 1792
block1_conv2 (Conv2D) (None, 128, 128, 64) 36928
block1_pool (MaxPooling2D) (None, 64, 64, 64) 0
block2_conv1 (Conv2D) (None, 64, 64, 128) 73856
block2_conv2 (Conv2D) (None, 64, 64, 128) 147584
block2_pool (MaxPooling2D) (None, 32, 32, 128) 0
block3_conv1 (Conv2D) (None, 32, 32, 256) 295168
block3_conv2 (Conv2D) (None, 32, 32, 256) 590080
block3_conv3 (Conv2D) (None, 32, 32, 256) 590080
block3_pool (MaxPooling2D) (None, 16, 16, 256) 0
block4_conv1 (Conv2D) (None, 16, 16, 512) 1180160
block4_conv2 (Conv2D) (None, 16, 16, 512) 2359808
block4_conv3 (Conv2D) (None, 16, 16, 512) 2359808
block4_pool (MaxPooling2D) (None, 8, 8, 512) 0
block5_conv1 (Conv2D) (None, 8, 8, 512) 2359808
block5_conv2 (Conv2D) (None, 8, 8, 512) 2359808
block5_conv3 (Conv2D) (None, 8, 8, 512) 2359808
block5_pool (MaxPooling2D) (None, 4, 4, 512) 0
global_average_pooling2d_1 (None, 512) 0
(GlobalAveragePooling2D)
dense_2 (Dense) (None, 100) 51300
dropout_4 (Dropout) (None, 100) 0
dense_3 (Dense) (None, 64) 6464
dense_4 (Dense) (None, 2) 130
=================================================================
Total params: 14,772,582
Trainable params: 57,894
Non-trainable params: 14,714,688
_________________________________________________________________
VGG16 Model Training Result
t_epochs= 15 if FAST_RUN else 50
transfer_history = transfer_model.fit(
train_generator,
epochs=t_epochs,
validation_data=valid_generator,
validation_steps= total_valid //batch_size,
steps_per_epoch= total_train // batch_size,
callbacks= callbacks
)Epoch 1/15
1333/1333 [==============================] - ETA: 0s - loss: 0.4172 - accuracy: 0.8070WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 485s 363ms/step - loss: 0.4172 - accuracy: 0.8070 - lr: 0.0010
Epoch 2/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3572 - accuracy: 0.8415WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 469s 352ms/step - loss: 0.3572 - accuracy: 0.8415 - lr: 0.0010
Epoch 3/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3458 - accuracy: 0.8486WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 508s 381ms/step - loss: 0.3458 - accuracy: 0.8486 - lr: 0.0010
Epoch 4/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3391 - accuracy: 0.8530WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 516s 387ms/step - loss: 0.3391 - accuracy: 0.8530 - lr: 0.0010
Epoch 5/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3321 - accuracy: 0.8576WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 482s 362ms/step - loss: 0.3321 - accuracy: 0.8576 - lr: 0.0010
Epoch 6/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3314 - accuracy: 0.8572WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 462s 347ms/step - loss: 0.3314 - accuracy: 0.8572 - lr: 0.0010
Epoch 7/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3305 - accuracy: 0.8571WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 491s 368ms/step - loss: 0.3305 - accuracy: 0.8571 - lr: 0.0010
Epoch 8/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3243 - accuracy: 0.8580WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 508s 381ms/step - loss: 0.3243 - accuracy: 0.8580 - lr: 0.0010
Epoch 9/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3229 - accuracy: 0.8642WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 512s 384ms/step - loss: 0.3229 - accuracy: 0.8642 - lr: 0.0010
Epoch 10/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3250 - accuracy: 0.8595WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 654s 491ms/step - loss: 0.3250 - accuracy: 0.8595 - lr: 0.0010
Epoch 11/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3205 - accuracy: 0.8661WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 604s 453ms/step - loss: 0.3205 - accuracy: 0.8661 - lr: 0.0010
Epoch 12/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3208 - accuracy: 0.8661WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 614s 460ms/step - loss: 0.3208 - accuracy: 0.8661 - lr: 0.0010
Epoch 13/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3189 - accuracy: 0.8665WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 613s 460ms/step - loss: 0.3189 - accuracy: 0.8665 - lr: 0.0010
Epoch 14/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3196 - accuracy: 0.8634WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 576s 432ms/step - loss: 0.3196 - accuracy: 0.8634 - lr: 0.0010
Epoch 15/15
1333/1333 [==============================] - ETA: 0s - loss: 0.3156 - accuracy: 0.8671WARNING:tensorflow:Early stopping conditioned on metric `val_loss` which is not available. Available metrics are: loss,accuracy
WARNING:tensorflow:Learning rate reduction is conditioned on metric `val_acc` which is not available. Available metrics are: loss,accuracy,lr
1333/1333 [==============================] - 644s 483ms/step - loss: 0.3156 - accuracy: 0.8671 - lr: 0.0010정확도가 약 87%로 상승한것을 볼수 있습니다!
'Kaggle' 카테고리의 다른 글
| Date Fruit Datasets (0) | 2022.05.17 |
|---|