사이킷런으로 수행하는 타이타닉 생존자 예측
타이타닉 생존자 test,train.csv 들은 https://www.kaggle.com/c/titanic/data 링크에서 다운받을수 있습니다.
- 이때까지 배웠던 Numpy,Pandas API를 정리
파일을 불러서 DataFrame 형태로 변환
seaborn 라이브러리를 통해서, 데이터를 시각화
info() 함수를 통해서, dataFrame의 데이터정보를 불러옴

fillna() 함수를 통해서, Null(Nan)값을 함수 인자값으로 대체

fillna() 함수를 통해 Nan값 모두 제거 되었음을 확인할 수 있다

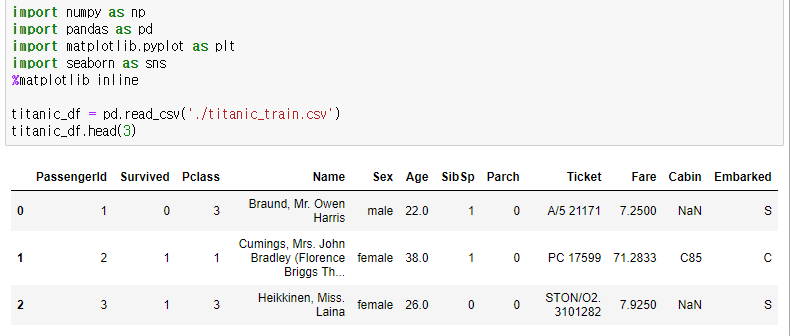
value_counts()를 통해, 해당 series값을 count를 할 수 있다.
DataFrame 내에 Cabin 열의 값들을 한글자로 바꾸기위해서, 인덱싱을 하는데
이때 str을 반드시 표시해주어야한다.

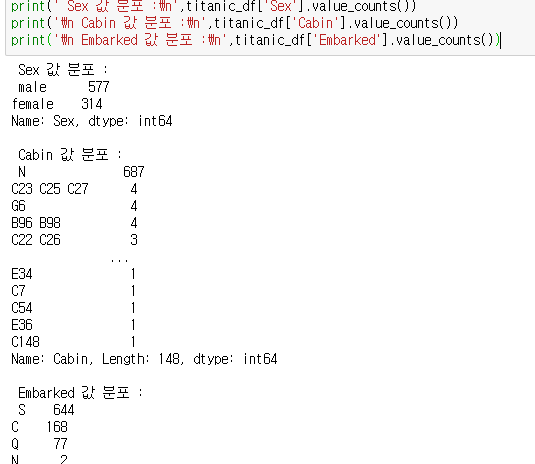
성별에 따른 생존여부를 파악 해보기
groupby를 통해, 'sex','Survived로 해당 데이터를 그룹화 한후, Survived를 count
(타이타닉에서, 노인과 여성이 1순위 구출대상)

생존 비교 데이터를 시각화 해보면 , Seaborn에 있는 barplot을 사용
seaborn.barplot(x='col1',y='col2',data = DataFrame)
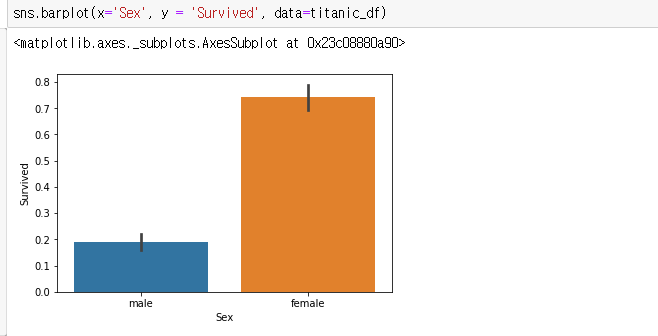
이제, 당시의 타이타닉호의 선실등급에 따른 생존여부도 살펴보자
barplot에는 hue 라는 인자도 있는데 hue에 대한 컬럼을 같이 비교시켜준다

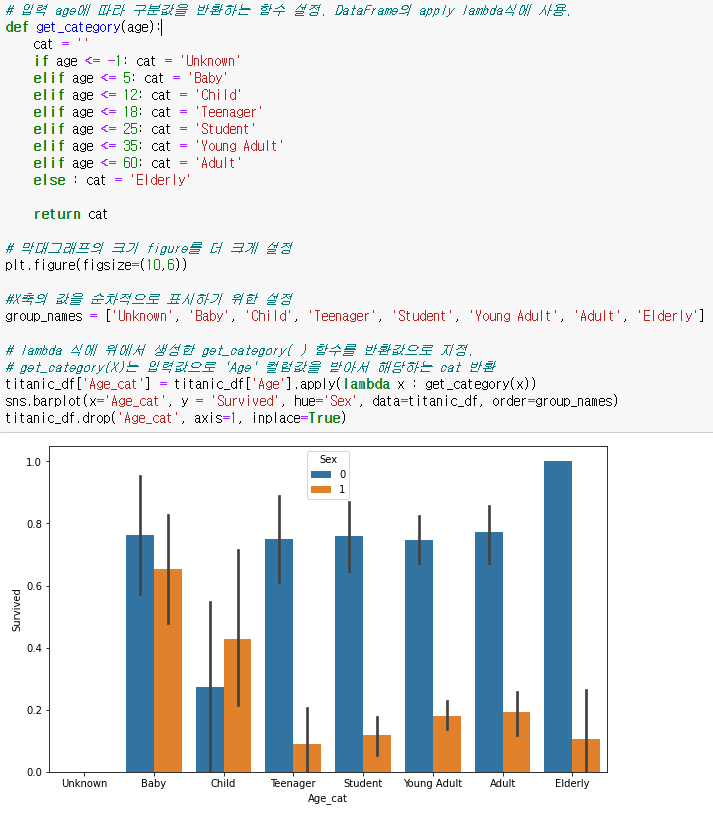
각 나이별 생존자 그래프 살펴보기
get_category() 함수를 만든후, apply(lambda x : ) 식을 사용
drop('컬럼명',axis=1(열삭제)) 를통해, Age_cat 열삭제
LabelEncoder를 통한 숫자형 카테고리로 변환
- LabelEncoder 객체는 카테고리 값의 유형 수에 따라 0~(카테고리 유형 수-1)까지의 숫자값으로 변환
LabelEncoder 객체의 fit(),transform()을 통해서, 값을변환
fit() 함수 내에, 바꾸고자 하는 문자열 카테코리 feature을 넣은후,
DataFrame[feature] = Encoder객체.transform(숫자형으로 바꾸고자 하는 카테고리 피쳐)

해당 결과를 보면 , Cabin,Sex,Embarked가 모두 숫자형으로 변환된 것을 알 수 있다.
train_test_split() API
train_test_split()을 통해, 테스트 데이터 세트와, 훈련 데이터 세트를 분류

train_test_split(Data,target,테스트데이터비율(20%),난수생성)
fit(),predict()를 통한 학습 및 예측

위에서, X_train,y_train,X_test,y_test 를 구별했으므로, 이에 대한값들은 단순히 넣어주기만 하면된다.
각 사용할 ML알고리즘 객체에 DataFrame.fit(훈련 데이터 세트,결과 데이터 세트)로 훈련 시킨후,
DataFrame.predict(테스트 데이터 세트)를 통해 테스트 결과 데이터 세트와, y_test를
accuracy_score() API를 통해, 정확도 측정
교차검증 ( kFold, cross_val_score(), GridSearch )
- KFold

kFold(분할할 데이터의 등분 수 n) : DataFrame의 데이터를 n개의 데이터로 분할
kfold.split()를 호출하면 학습용/검증용 데이터로 분할할 수 있는 인덱스를 반환하므로,
X_train,X_test = X_titanic_df.values[train_index]와 같은 형태로 인덱스를 이용하여 데이터를 받아야함
Enumerate란?
- 반복문 사용 시 몇 번째 반복문인지 확인이 필요할 수 있는데, 이때 사용
- 인덱스 번호와 컬렉션의 원소를 튜플형태로 반환
arr = [10,2,3,510]
for i in enumerate(arr):
print(i)
# 출력결과
(0,10)
(1,2)
(2,3)
(3,510)
- cross_val_score()
- 폴드 세트를 설정한후,
- for 루프에서 반복으로 학습 및 테스트 데이터의 인덱스를 추출한 뒤
- 반복적으로 학습과 예측을 수행하고 예측 성능을 반환
이 일련의 과정을 한꺼번에 수행해주는 API 이다
cross_val_score(estimator,X,y,scoring,cv)로 선언할 것이며, 기본의 인자형태는 더욱더 길다
| estimator | 사이킷런 분류알고리즘 Classifier / Regressor |
| X | Feature 데이터 세트 |
| y | label 데이터 세트 |
| scoring | 예측 성능 평가 지표를 기술 |
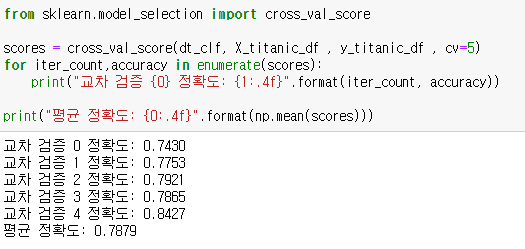
dt_clf = DecisionTreeClassifier 로 위에서 선언,
X = 생존자 피처 데이터 세트
y = 생존자 레이블 데이터 세트
cv = 5 라는것은 n_split = 5와 같다 (각 훈련 데이터를 30개로 나눈후,5회반복)
cross_val_score의 반환값은 배열 형태로 반환이 되므로, 이 코드에서는 cv =5 이므로 값이 5개일것이다.
[0.7430,0.7753,0.7921,0.7865,0.8427]
- GridSearchCV
교차 검증과 최적 하이퍼 파라미터 튜닝을 한번에 할 수있는 알고리즘 이다.
하이퍼 파라미터란?
머신러닝 알고리즘을 구성하는 주요 구성 요소이며, 이값을 조정해 알고리즘의 예측 성능을 개선 할 수 있다.

- param_grid : key + 리스트 값을 가지는 딕셔너리가 주어지고, estimator의 튜닝을 위해 파라미터 명과 사용될 여러 파라미터 값을 지정
- refit : 디폴트가 True이며, True로 생성 시 가장 최적의 하이퍼 파라미터를 찾은뒤 입력된 estimator 객체를 해당 하이퍼 파라미터로 재학습시킨다
parameters 통해 각각의 하이퍼 파라미터를 추출후, 최고의 파라미터로 재학습 시키는 코드
학습에 도움이 된 출처
1.파이썬 머신러닝 완벽가이드 -권철민
'# AI 이론 > Machine Learning' 카테고리의 다른 글
| [ML]캐글 신용카드 사기 검출 (0) | 2022.02.05 |
|---|---|
| LightGBM (0) | 2022.01.26 |
| XGBoost 소개(파이썬 Wrapper, 싸이킷런 Wrapper) 및 예제 (0) | 2022.01.26 |
| 피처 스케일링(Feature Scaling) (0) | 2022.01.19 |
| 1.머신러닝이란? (0) | 2022.01.04 |