LightGBM이란
XGBoost와 함께 부스팅 계열 알고리즘에서 가장 각광을 받고 있다.
XGboost의 경우 뛰어난 부스팅 알고리즘이지만, 여전히 학습시간이 오래걸리는데, 특히 GridSearchCV로 하이퍼 파라미터 튜닝을 수행하다 보면 수행시간이 너무 오래걸리는것을 알수있다.
LightGBM의 큰장점은 XGBoost보다 학습에 걸리는 시간이 훨씬 적다는 점이다.
- LightGBM은 XGBoost의 예측 성능에 별차이가 없지만, 기능상 다양성은 LGBM이 더많다.
- LGBM의 단점은 적은 데이터 세트에 적용할 경우 과적합이 발생하기 쉽다는 것
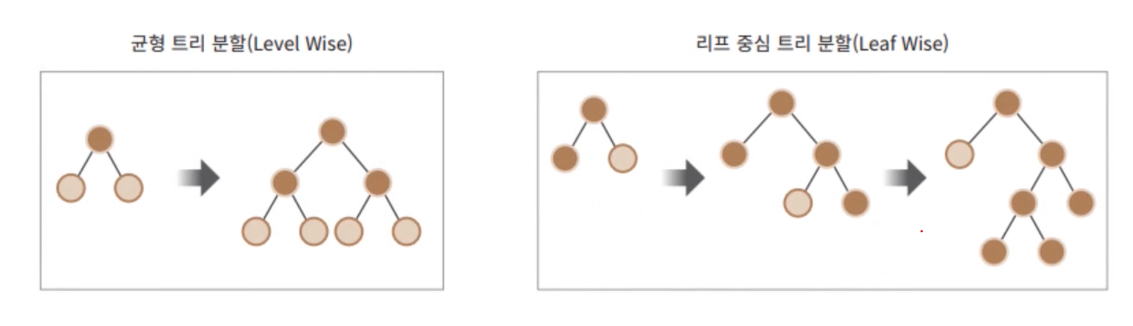
일반적으로 10,000건 이하의 데이터 세트 정도라고 LightGBM 공식문서에 기술되어있다. - 기존의 GBM계열의 트리분할은 리프 중심 트리 분할 이였지만, 시간이 오래걸린다는 단점이있었다.
이에 LightGBM은 리프 중심 트리분할을 통해, 예측 오류 손실을 최소화 할 수 있다라는 구현사상을 가졌다.
주요 파라미터
| num_iterations[default=100] | 반복수행하려는 트리의 개수 지정(사이킷런에서 XGB의 n_estimators 과 같은 파라미터) |
| learning_rate[dafault = 0.1] | 0~1사이의 값을 지정하며, 부스팅 스텝을 반복적으로 수행할 때 업데이트 되는 학습률 값 (n_estimators를 크게하고, learning_rate를 작게해서 예측성능을 주로할 수있음) |
| max_depth[default =-1] | 트리 기반 알고리즘의 max_depth와 같다. 0보다 작은값으로 지정시, 깊이에 대한 제한이 없음 |
| min_data_in_leaf[default =20] | DecisionTree의 min_samples_leaf와 같음 * 사이킷런 LGBM에서는 min_child_samples로 쓴다 "최종 결정 클래스인 리프노드가 되기 위해서 최소한으로 필요한 레코드의 수" |
| num_leaves | 하나의 트리가 가질 수 있는 최대 리프 개수 |
| boosting[default =gbdt] | 부스팅의 트리를 생성하는 알고리즘을 기술 gbdt : 일반적 그래디언트 부스팅 결정트리 rf : 랜덤 포레스트 |
| bagging_fraction[default = 1.0] | 트리가 커져서 과적합 되는 것을 제어하기 위해, 데이터를 샘플링 하는 비율을 지정 *사이킷런LightGBMClassifier에서는 subsample로 변경 |
| feature_fraction[default = 1.0] | 개별 트리를 학습할 때마다 무작위로 선택하는 피처의 비율 과적합을 막기위해 사용 (LightGBMClassifier : colsample_bytree 로 변경) |
| lambda_l2[default = 0.0] | L2 regulation 제어용 reg_lambda로 변환 |
| lambda_l1[default =0.0] | L1 regulation 제어용 reg_alpha로 변환 |
Learning Task 파라미터
- objective : 최솟값을 가져야 할 손실함수를 정의 (XGBoost의 objective 파라미터와동일)
회귀,다중 클래스 분류, 이진분류에 따라 objective인 손실함수가 지정
파이썬 래퍼 LigthGBM과 사이킷런 래퍼 XGBoost, LightGBM 하이퍼 파라미터 비교
| 유형 | 파이썬 래퍼 LightGBM | 사이킷런 래퍼 LightGBM | 사이킷런 래퍼 XGBoost |
| 파라미터 명 | num_iterations | n_estimators | n_estimators |
| learning_rate | learning_rate | learning_rate | |
| max_depth | max_depth | max_depth | |
| min_data_in_leaf | min_child_samples | N/A | |
| bagging_fraction | subsample | subsample | |
| feature_fraction | colsample_bytree | colsample_bytree | |
| lambda_l2 | reg_lambda | reg_lambda | |
| labmda_l1 | reg_alpha | reg_alpha | |
| early_stopping_round | early_stopping_round | early_stopping_round | |
| num_leaves | num_leaves | N/A | |
| min_sum_hessian_in_leaf | min_child_weight | min_child_weight |
LightGBM적용 - 위스콘신 유방암 예측
#LightGBM의 파이썬 패키지인 lightgbm에서 LGBMClassifier
from lightgbm import LGBMClassifier
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
dataset = load_breast_cancer()
ftr = dataset.data
target = dataset.target
# 데이터 세트 추출 80% 훈련 20% 테스트용
X_train,X_test,y_train,y_test = train_test_split(ftr,target,test_size = 0.2,random_state =156)
lgbm_wrapper = LGBMClassifier(n_estimators = 400) # 반복수행하려는 트리의 개수
evals = [(X_test,y_test)] # 성능평가를 할 데이터 세트
lgbm_wrapper.fit(X_train,y_train,early_stopping_rounds =100,
eval_metric = "logloss", eval_set = evals,verbose = True)
preds = lgbm_wrapper.predict(X_test)
pred_proba= lgbm_wrapper.predict_proba(X_test)[:,1]결과
[1] valid_0's binary_logloss: 0.565079
[2] valid_0's binary_logloss: 0.507451
[3] valid_0's binary_logloss: 0.458489
[4] valid_0's binary_logloss: 0.417481
[5] valid_0's binary_logloss: 0.385507
....
....
[142] valid_0's binary_logloss: 0.196367
[143] valid_0's binary_logloss: 0.19869
[144] valid_0's binary_logloss: 0.200352
[145] valid_0's binary_logloss: 0.19712
#plot_importance()를 이용해 피처 중요도 시각화
from lightgbm import plot_importance
import matplotlib.pyplot as plt
%matplotlib inline
fig,ax = plt.subplots(figsize= (10,12))
plot_importance(lgbm_wrapper,ax =ax)
'# AI 이론 > Machine Learning' 카테고리의 다른 글
| 선형회귀(GD,Ridge,Lasso,ElasticNet) (0) | 2022.03.30 |
|---|---|
| [ML]캐글 신용카드 사기 검출 (0) | 2022.02.05 |
| XGBoost 소개(파이썬 Wrapper, 싸이킷런 Wrapper) 및 예제 (0) | 2022.01.26 |
| 피처 스케일링(Feature Scaling) (0) | 2022.01.19 |
| [Sklearn]타이타닉 생존자 예측 (0) | 2022.01.14 |