데이터 분석전 알아야 할 지식정리
Log변환
- 왜곡된 분포도를 가진 데이터 세트를 비교적 정규 분포에 가깝게 변환해주는 Feature Engineering 방식
- Skrew 된 분포도 대부분을 로그변환으로 바꾸는것을 권장
IQR
- IQR(Inter Quantile Range)를 통한 Outlier Removal(이상치 제거)
- Box Flot 을 통해, 범위 밖에있는 값들은 이상치로 간주
UnderSampling And OverSampling
- UnderSampling : 많은 레이블을 가진 데이터세트를 적은 레이블 세트만큼 감소 시킴
- OverSampling : 적은 레이블을 가진 데이터세트를 증식시켜, 많은 레이블 세트만큼 부풀림
- (SMOTE방식을 통해 OverSampling을 실시)
- SMOTE : 적은 데이터 세트에 있는 개별 데이터들의 K 최근접이웃(KNN)을 찾아서 이 데이터와
K개 이웃들의 차이를 일정 값으로 만들어서 기존 데이터와 약간 차이가 나는 새로운 데이터 생성
캐글 신용카드 사기 검출
Kaggle의 신용카드 데이터 세트를 이용해 신용카드 사기 검출 분류 실습
- 해당 데이터 세트의 레이블인 Class 소고성은 매우 불균형한 분포를 가지고있음
- Class는 0,1로 분류되는데, 0은 정상적인 트랜잭션 데이터 , 1은 사기 트랜잭션
- 전체 데이터의 0.172%만 사기데이터
데이터를 로딩 시킨후, 3개의 데이터를 읽음

데이터 세트를 Train,Test로 나누는 함수 작성
stratify = y_labels : y_labels의 값에 분포도에 따라서 학습과 테스트 데이터를 맞춰서 분할
Class가 1인 데이터가 극도로 적기때문!

임의의 Classifier에 대해서, Test결과를 나타내는 함수 생성

이처럼 데이터가 불균형하게 분포되어 있을때는 정규화를 시켜주는것이 좋다.
StandardScaler 함수를 사용
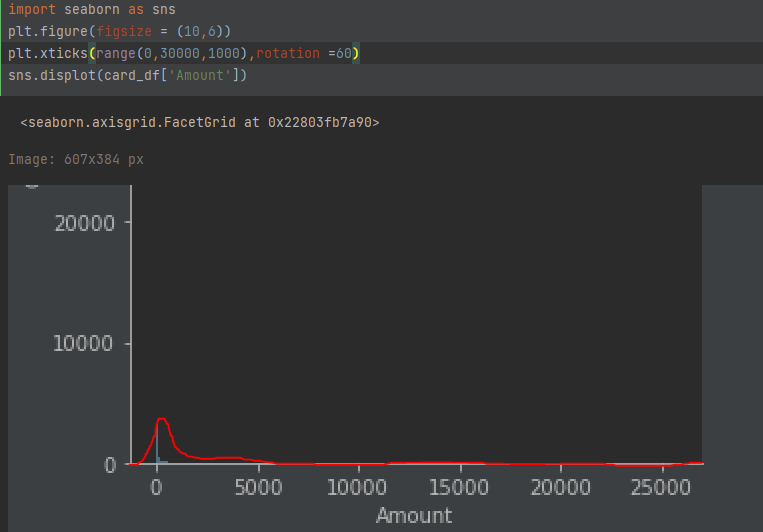


log1p 값으로 변환하는것이 원래 큰값을 상대적으로 작은 값으로 변환하기 때문에, 데이터 분포도의 왜곡을 상당 수준 개선해 준다.
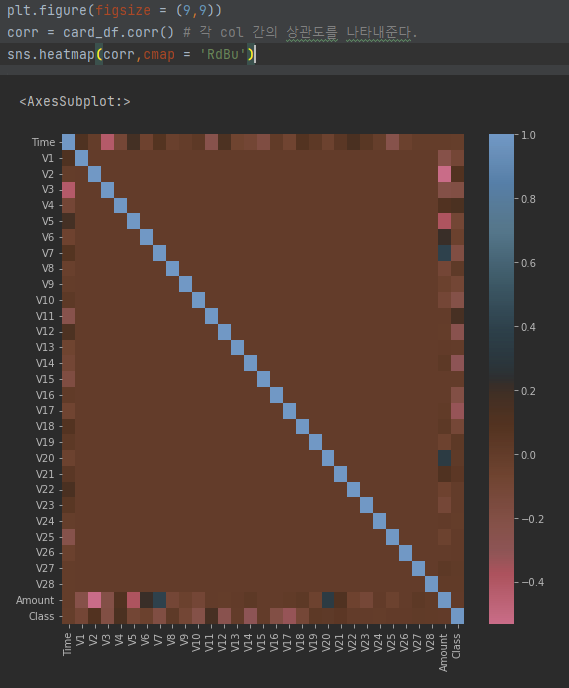
corr() 함수를 통해 컬럼간의 상관도를 나타내준다.
당연하게, 대각선의 그래프는 모두 파란색인데, 값마다 해당하는것이 자기자신의 열이기 때문이다.
Class 피처와 음의 상관관계가 높은 V14,V17를 살펴볼 수 있다.
IQR을 계산하여, V14 컬럼에 대해 이상치 인덱스를 찾아보자

- get_outlier()
- fraud를 통해 Class=1인 사기검출의 해당열을 검출
- quantile_25 = 상위 25%의 값, quantile_75 = 상위 75%의 값
- iqr은 Q75 -Q25를 뺀 값이다. 이때, 가중치를 곱하여 최솟값,최대값을 구할수 있다.
- Q25 - iqr_weight = 이상치내의 최솟값 ,Q75-iqr_weight = 이상치내의 최댓값
- fraud[(fraud < lowest_val) |(fraud > highest_val)].index 를 통해 범위 외의 값의 인덱스를 반환

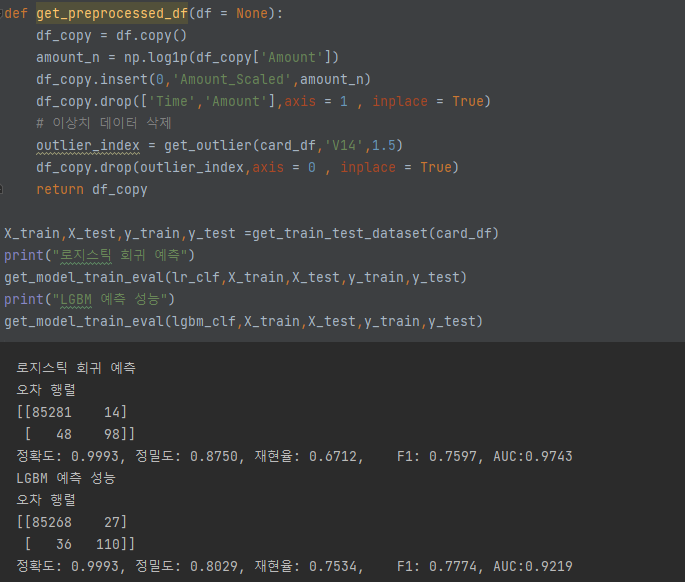
이상치를 찾아서 제거후, Logistic Regression, LGBMClassifier의 예측 결과
SMOTE를 통한 데이터 오버샘플링

해당 오버샘플링후 성능은 어떨까?

OverSampling 후 정밀도가 형편없이 굉장히 낮다.
왜 그런것일까?
precision_recall 함수를 사용해서 보면 임계값 0.99 이하에서는 재현율이 매우좋고, 정밀도가 극단적으로 낮다가, 0.99 이상에서는 재현율이 대폭 떨어지고 정밀도가 높아지는것을 알수있다.
분류 결정 임계값을 조정하더라도, 임계값의 민감도가 너무 심해 올바른 재현율/정밀도 성능을 알수 없다.

'# AI 이론 > Machine Learning' 카테고리의 다른 글
| 주성분 분석(PCA)란? (0) | 2022.04.06 |
|---|---|
| 선형회귀(GD,Ridge,Lasso,ElasticNet) (0) | 2022.03.30 |
| LightGBM (0) | 2022.01.26 |
| XGBoost 소개(파이썬 Wrapper, 싸이킷런 Wrapper) 및 예제 (0) | 2022.01.26 |
| 피처 스케일링(Feature Scaling) (0) | 2022.01.19 |