오늘날 대부분의 머신러닝 애플리케이션이 지도학습 기반이지만, 사용할 수 있는 데이터는 대부분 레이블이 존재하지 않습니다. 이러한 레이블이 없는 데이터에 숨겨진 패턴을 찾아내고 구조화하는 머신러닝 기법을 비지도학습(Unsupervised Learning)이라고 하는데, 비지도학습 알고리즘 중 가장 널리알려진 K-Means Clustering 알고리즘에 대해서 알아보겠습니다.
군집은 다음과 같은 다양한 애플리케이션에서 사용됩니다.
- 고객분류
- 데이터분석
- 차원 축소 기법
- 이상치 탐색
- 준지도 학습
- 검색 엔진
- 이미지 분할 등..
K-Means Clustering
- "K"는 주어진 데이터로부터 그룹화 할 그룹의 개수, 즉 클러스터의 개수
- "Means"는 각 클러스터의 중심과 데이터들의 평균거리를 의미
- 센트로이드(centroids)는 클러스터의 중심을 의미
K-Means 알고리즘은 다음과 같이 수행이 됩니다.
- 데이터셋에서 무작위로 균등하게 K 개의 센트로이드를 선택합니다.
- 각 데이터들을 가장 가까운 센트로이드가 속한 그룹으로 지정합니다.
- 2번과정에서 할당된 결과를 통해서 센트로이드를 재설정합니다.
- 센트로이드의 값이 변하지 않을때까지 2~3번 과정을 반복합니다.

Make_blobs Data를 활용한 K-Means Clustering
make_blobs 는 모든방향으로 같은 성질을 가지는 정규분포를 이용해 가상데이터를 생성하는 함수입니다.
주로 클러스터링용 가상데이터를 생성하는데 사용됩니다.
예제를 보면서 설명하겠습니다.

paramater로는 샘플의수, 중심위치, 표준편차를 받습니다. 이 데이터의 분포도를 살펴보겠습니다.
데이터 분포도를 그리는 코드입니다.
↓↓↓↓↓↓↓↓↓
def plot_clusters(X, y=None):
plt.scatter(X[:, 0], X[:, 1], c=y, s=1)
plt.xlabel("$x_1$", fontsize=14)
plt.ylabel("$x_2$", fontsize=14, rotation=0)
plt.figure(figsize=(8, 4))
plot_clusters(X)
plt.show()
왼쪽에 3개의 데이터가 분포된곳이 표준편차가 0.1이고 중심과 오른쪽의 표준편차가0.3, 0.4가 되겠네요
Training and Prediction K-Means Clustering (sklearn)
sklearn 라이브러리의 cluster 모듈에 K-Means를 구현할 수 있는 KMeans를 제공합니다.

KMeans로 모델을 생성할 시, 클러스팅 할 그룹의 수를 지정해주어야 합니다. 이는 n_clusters = k 옵션으로 설정할 수 있습니다.
다른 estimators들과 같이 fit_predict(Train_data)를 통해서 학습을 수행합니다.

이때 fit()을 통해서 각 샘플은 5개의 클러스터 중 하나에 할당됩니다

각 클러스터 중심(위의 예제는5개)를 찾으려면 cluster_centers_ 를 이용하면됩니다.

이제 5개의 군집으로 나눈후에 이 데이터들이 어떻게 군집화가 이루어졌는지 살펴 보겠습니다.
데이터 분포도를 그리는 코드입니다.
↓↓↓↓↓↓↓↓↓
def plot_data(X):
plt.plot(X[:, 0], X[:, 1], 'k.', markersize=2)
def plot_centroids(centroids, weights=None, circle_color='w', cross_color='k'):
if weights is not None:
centroids = centroids[weights > weights.max() / 10]
plt.scatter(centroids[:, 0], centroids[:, 1],
marker='o', s=35, linewidths=8,
color=circle_color, zorder=10, alpha=0.9)
plt.scatter(centroids[:, 0], centroids[:, 1],
marker='x', s=2, linewidths=12,
color=cross_color, zorder=11, alpha=1)
def plot_decision_boundaries(clusterer, X, resolution=1000, show_centroids=True,
show_xlabels=True, show_ylabels=True):
mins = X.min(axis=0) - 0.1
maxs = X.max(axis=0) + 0.1
xx, yy = np.meshgrid(np.linspace(mins[0], maxs[0], resolution),
np.linspace(mins[1], maxs[1], resolution))
Z = clusterer.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(Z, extent=(mins[0], maxs[0], mins[1], maxs[1]),
cmap="Pastel2")
plt.contour(Z, extent=(mins[0], maxs[0], mins[1], maxs[1]),
linewidths=1, colors='k')
plot_data(X)
if show_centroids:
plot_centroids(clusterer.cluster_centers_)
if show_xlabels:
plt.xlabel("$x_1$", fontsize=14)
else:
plt.tick_params(labelbottom=False)
if show_ylabels:
plt.ylabel("$x_2$", fontsize=14, rotation=0)
else:
plt.tick_params(labelleft=False)
plt.figure(figsize=(8, 4))
plot_decision_boundaries(kmeans, X)
plt.show()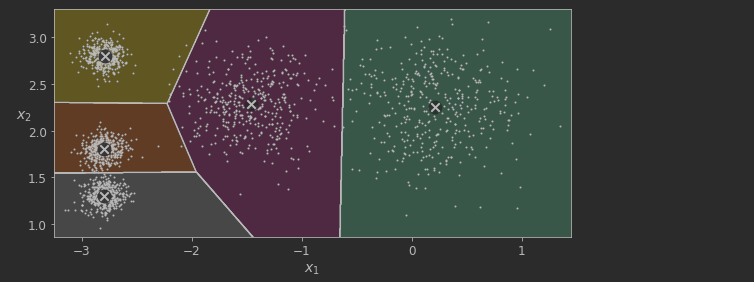
나쁘지 않게 잘 클러스터링이 이루어진거 같습니다.
이너셔(Inertia)
최선의 모델을 선택하려면 K-평균 모델의 성능을 평가할 방법이 있어야 합니다. 하지만, 군집은 비지도 학습이기 때문에
타깃이 존재하지 않습니다. 하지만 적어도 각 샘플과 센트로이드 사이의 거리를 측정할 수 있는데, 이것이 이니셔 지표의 아이디어입니다.
k-평균 알고리즘은 클러스터 중심과 클러스터에 속한 샘플 사이의 거리를 잴 수 있는데,
이 거리의 제곱 합을 이너셔(intertia)라고 부릅니다.
이너셔는 클러스터에 속한 샘플이 얼마나 가깝게 모여 있는지를 나타내는 값을 나타냅니다.
엘보우 방법은 클러스터수를 늘려나가면서 이너셔(intertia)의 변화를 관찰하여 최적의 클러스터 개수를 찾는 방법
으로, 클러스터 개수를 증가 시켜서 이너셔를 그래프로 그리면 감소하는 속도가 꺾이는 지점이 존재합니다.
이 지점을 Elbow 지점이라고 합니다.
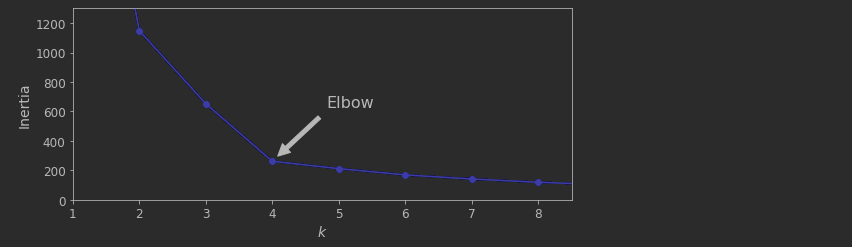
k = 4 에서 엘보우가 존재합니다. 이 값보다 클러스터가 작으면 나쁘다는 뜻이고, 더많으면 크게 도움이 되지 않습니다.
k= 4 가 아주 좋은 선택이지만, 물론 이 예제에서는 이 값이 완벽하지는 않습니다.
아래의 사진과같이 k=4일때 군집화가 이루어집니다.
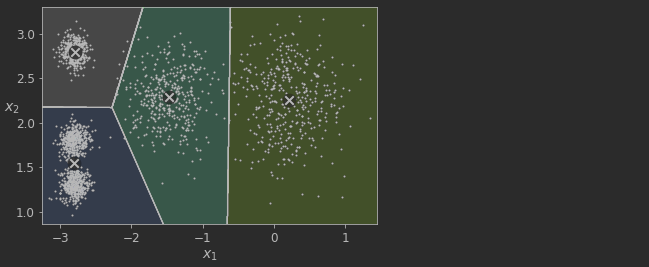
Review
이번 글에서 비지도학습 중 K-Means Clustering에 대해서 정리를 했습니다.
이너셔를 통해서 최적의 클러스터 값을 찾는 연습도 했지만 정확하지는 않습니다. 다른 방식의 클러스터 k 값을 찾는 방식(Silhouette_score)이 존재도하고, K-Means의 데이터의 형태에 따른 한계점도 존재합니다.
이 내용을 바탕으로 minibatchKMeans와 Silhouette 계수에 대해서 알아보는것이 좋을 것 같습니다.
'# AI 이론 > Machine Learning' 카테고리의 다른 글
| 주성분 분석(PCA)란? (0) | 2022.04.06 |
|---|---|
| 선형회귀(GD,Ridge,Lasso,ElasticNet) (0) | 2022.03.30 |
| [ML]캐글 신용카드 사기 검출 (0) | 2022.02.05 |
| LightGBM (0) | 2022.01.26 |
| XGBoost 소개(파이썬 Wrapper, 싸이킷런 Wrapper) 및 예제 (0) | 2022.01.26 |