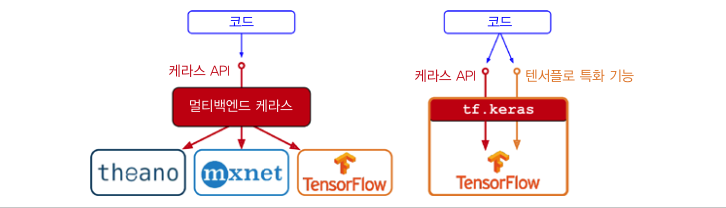
시계열 데이터를 다룰때 사용하는 메서드입니다. Batch 사용하기 range_ds = tf.data.Dataset.range(10000) # Using Batch batches = range_ds.batch(10,drop_remainder=True) for batch in batches.take(5): print(batch.numpy()) # Outputs [0 1 2 3 4 5 6 7 8 9] [10 11 12 13 14 15 16 17 18 19] [20 21 22 23 24 25 26 27 28 29] [30 31 32 33 34 35 36 37 38 39] [40 41 42 43 44 45 46 47 48 49] 한 단계 앞선 데이터를 예측하기 위한 메서드 입니다 def dense_1_step(b..