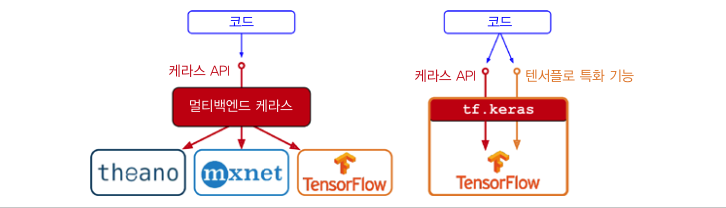
Protocol Buffer CSV,XML,JSON등 여러 직렬화 방식 중 하나로 구글에서 개발한 이진 직렬화 방식 직렬화(Serialization)란 직렬화란 시스템 내부에서 사용하는 개체를 다른 시스템에서도 사용할 수 있도록 바이트 형태로 데이터를 변환하는 기술을 뜻한다. 예를들면 Java,Python에서 사용하던 객체 방식과 Node.js에서는 형식이 다르기 때문에 모두가 같은 데이터를 사용하도록 공통화 작업을 한다고 생각하면 된다 ProtoBuf 사용순서 protoBuf 포맷으로 데이터 구조를 정의 컴파일하기(각 타겟 언어별 protoc 컴파일러 사용) 컴파일된 모듈 각 언어에서 코드레벨로 로드하기 ProtoBuf 파일 생성 %%writefile person.proto syntax = "proto..